
How we can trick AI
AI algorithms, as machines, assume that the data they process is unbiased and originates from external sources. However, in many cases, the data is provided by individuals, who often distort it to serve their own interests. For instance, financial analysts bias their predictions for high commissions, while unqualified applicants tailor their resumes with targeted keywords to get past the filters.
How should we optimally respond to AI algorithms? Do these algorithms perform well against strategic data sources? Understanding these dynamics is crucial because they influence decision-making across sectors such as finance, online markets, and healthcare. My research aims to explore the interactions between self-interested individuals and algorithms, emphasizing the need for algorithms that account for strategic behavior. This approach can lead to the development of AI algorithms that perform better in complex and strategic environments.
Game theory meets AI: A model for strategic interactions
With this challenge in mind, with Vianney Perchet, a professor at the “Centre de recherche en économie et statistique” (CREST) at the ENSAE, we built a model based on game theory to analyze the interaction between a strategic agent and an AI algorithm.
Consider a repeated interaction between a financial analyst and an investor. Each day, the analyst forecasts the chances that an asset will be profitable. Analysts tend to inflate these chances in pursuit of commission from selling the asset. Therefore, the investor only wants to follow their recommendations if they are credible.
Consider an AI platform that uses a statistical test to verify how reliable the analyst’s predictions are. It only forwards the forecasts if they pass the “calibration test." This test checks whether the predictions match what actually happens. For example, if an analyst forecasts a 60% chance of profit over five days, the test checks if there was a profit on around three of those days. Calibration is essential for forecasting and is used to evaluate the accuracy of prediction markets.
Calibration test:
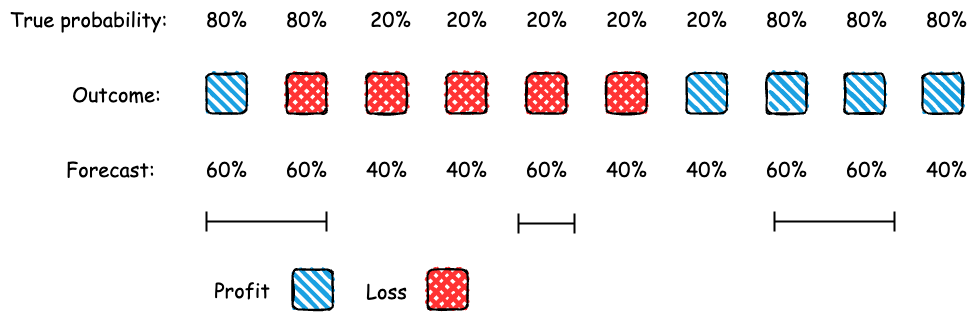
Since the analyst must pass the calibration test, what strategies can she use to send forecasts? A knowledgeable analyst can always pass the calibration test by honest reporting. For example, suppose that if an asset is profitable today, there’s an 80% chance it will be profitable tomorrow; if it’s not profitable today, there’s a 20% chance it will be profitable tomorrow. The analyst can truthfully report these probabilities to pass the calibration test.
Are there other ways for the analyst to pass the test? Yes, she could garble (or add noise to) the truthful forecasts. For instance, she could randomize between reporting 60% and 40% in a way that still allows her to pass the calibration test. While the forecasts must remain accurate, they can be less precise (or informative) than the truthful forecasts. This implies that strategic forecasting is possible, allowing the analyst to achieve better outcomes than by simply being truthful.
Why no-regret algorithms might regret their decisions
Besides the calibration test, we look at what happens when the investor uses no-regret learning algorithms for decision-making. Regret measures the difference between what one could have achieved and what one actually obtains. No-regret algorithms ensure that, in hindsight, an investor could not have done better by consistently making the same choice. However, we show that using a no-regret algorithm can lead to worse performance for the investor compared to relying on the calibration test.
We found that agents can manipulate the data to serve their own interests, which can cause the algorithm to perform poorly. Therefore, it is essential to understand who is supplying the data and what their motivations are. This underscores the pressing need to create performance benchmarks for algorithms in strategic environments.
The future of responsible AI
This research examines how individuals strategically interact with AI algorithms, focusing on data manipulation. By analyzing its impact on predictions and recommendations, this research opens new paths at the intersection of economics and computer science. These findings align with Hi! PARIS’s vision of advancing responsible AI research and can inform the design of robust AI systems that promote trust and reliability. This is particularly relevant in industries like finance and healthcare, where biased recommendations can lead to significant societal implications, such as economic disparities and unequal access to services.






